

Photo by Mariia Shalabaieva on Unsplash
Run your own Chatgpt alternative locally (Llama) on M1


If you’re reading this, you must have had the pleasure of using ChatGPT and wondered if they have an api that you can use in your own app or run locally on your machine. Well, the good news is, they do have an API but you only have a certain number of free tokens.
There are other solutions that you can use. With the boom of LLMs (Large Language Model), recently many companies have launched their own LLM like BERT, by google, Falcon 40B, etc. but meta’s LLM called Llama 2 comes absolutely free and can be used both personally and/or commercially. All you need to do is request the model from meta and here is how to go about it:
- Go to meta’s llama webpage, here:
Llama 2 - Meta AI
Llama 2 - The next generation of our open source large language model, available for free for research and commercialai.meta.com
2. Click on “Download the model”, which will take you to “Llama access request form”:
Llama access request form - Meta AI
Request access to the next version of Llama.ai.meta.com
3. Once you have filled out the request form, meta will send you an email with two links, one will be to their github repository and the other will be a long link starting with “download.llamamet.net….” . The github repostory link will take take you to meta’s llama github page. Clone this repo.
GitHub - facebookresearch/llama: Inference code for LLaMA models
Inference code for LLaMA models. Contribute to facebookresearch/llama development by creating an account on GitHub.github.com
4. Once cloned, run the “download.sh” from the repo, and it will ask you to “Enter the link from the email”, paste the “download.llamamet.net….” link here. After you’ve put the link in and specified the model you wish to download, it will start downloading the model weights. Make sure have enough memory. Just to give you an estimate of how big these files are, if you download all the models it’ll come to a little over 300 GBs.
5. Now, to run Llama on a m1 Mac, you need to clone another repository called “llama.cpp”. What “llama.cpp” does is that it provides “4 bit integer quantization” to run the model on Apple’s M1 mac. The repo can be found here:
GitHub - ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++
Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on…github.com
6. After cloning this repo, go inside the “llama.cpp” using the terminal and run the following command:
LLAMA_METAL=1 make
7. This will create our quantization file called “quantize”. Now inside the “llama.cpp” folder, find the “models” folder and inside this folder make a new folder. Call this whatever model you wish to use. For example: “7B” if its a 7 billion parameter model, “13B” if its a 13 billion parameter model, etc.
Inside this newly created folder paste the model that you downloaded when you entered the email from meta, along with “tokenizer_chechlist.chk” and “tokenizer.model” .
Time to run it:
8. Now go inside “llama.cpp” and install the required dependencies by running the following command:
python3 -m pip install -r requirements.txt
9. Run “convert.py” file before quantizing the model.
python3 convert.py models/7B-chat/
10. Now quanztize it, using the following command:
./quantize ./models/7B-chat/ggml-model-f16.bin ./models/7B-chat/ggml-model-q4_0.bin q4_0
This will look something like this:
11. Run the inference:
./main -m ./models/7B-chat/ggml-model-q4_0.bin -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt
I used the prompts folder in “llama.cpp”. The examples use “few shot learning” if I’m not mistaken. In this style of prompt, you provide a couple of “request and response” texts so that the model knows how to repond. Additionally, you can also write your own prompts and define the relationship.
Should look something like this:
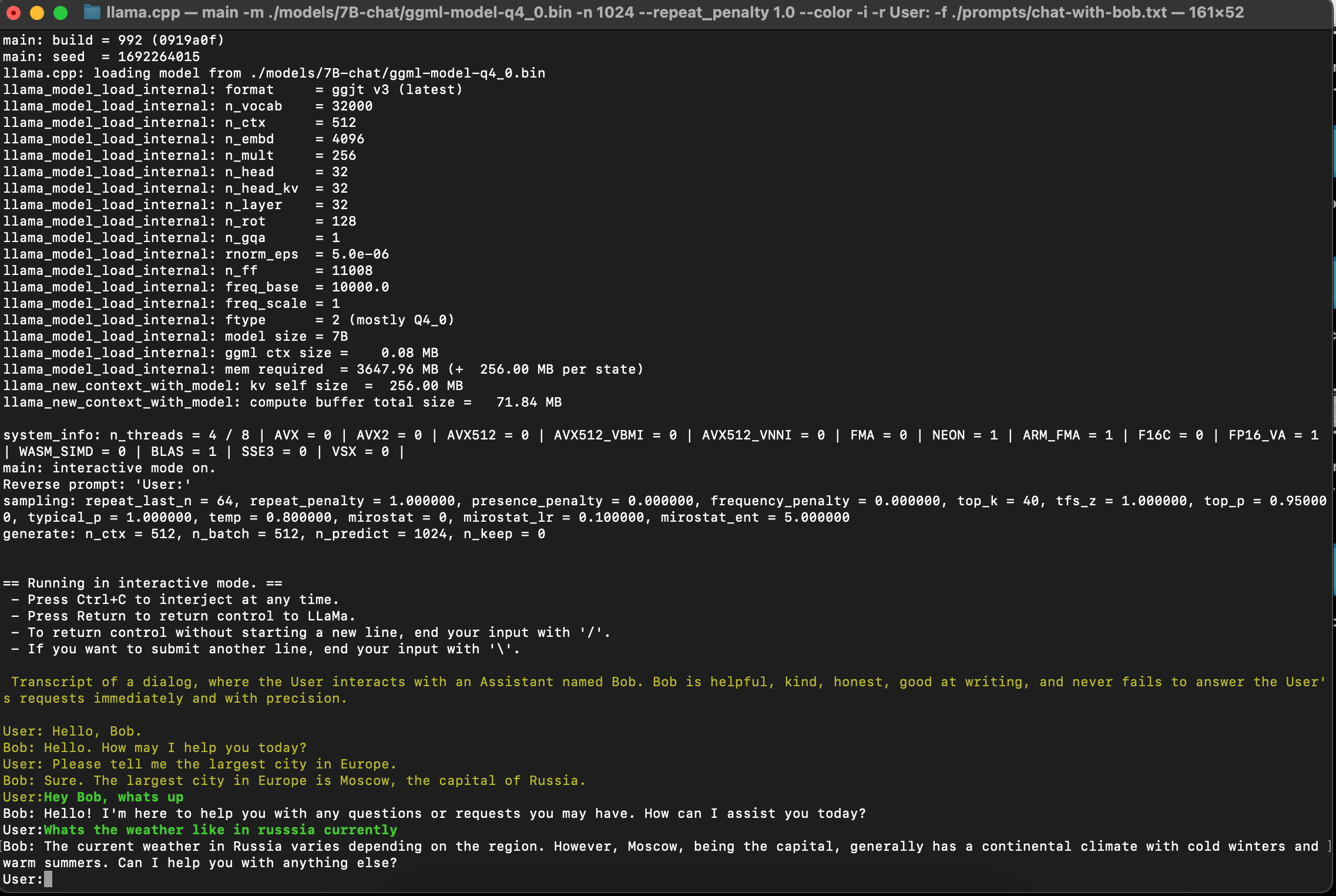
Enjoy talking to Bob!! Thank you.